Summary
System reliability and avoidance of down-time are themes that recur time and again with Smartvox customers. In this article I will review some of options available to a system designer who wants to build a highly available OpenSIPS solution, paying particular attention to the new Clusterer module which is at the heart of a set of new tools introduced in version 2.
The focus of my attention for the Clusterer module is to see if it can be used to help build a highly available solution. For example, can it work in an Active-Standby HA configuration or does it only makes sense in an Active-Active scenario? Also, high on my list of questions: Can the Clusterer module be sensibly used alongside the Linux High Availability solution built around Corosync and Pacemaker?
I will look at some solution architecture scenarios that an Internet Telephony Service Provider (ITSP) might choose to use to maximise the resilience and availability of their service. In each scenario I will explain the results of my investigations to see how best to leverage the power of the new Clusterer module and how to avoid some pitfalls that caught me out along the way.
About the Clusterer Module
Version 2.2 of OpenSIPS introduced a new CLUSTERER module. In conjunction with the “bin” protocol, it provides an underlying framework for replication of specific items of dynamic data used by other modules such as DIALOG and USRLOC. It allows replication between servers of:
- Contact details for registered devices
- Stateful dialog information (including “profiles” which can track the number of concurrent calls in user-defined categories)
- SIP traffic rates, allowing calls per second to be capped across multiple proxy servers
Data replication via the Clusterer module seamlessly integrates with the existing data caching features already present in many OpenSIPS modules. This brings significant performance advantages when compared with a solution that relies on conventional database replication mechanisms and has the potential to allow backup servers to already be pre-loaded with cached data when failover is triggered.
On the face of it, the Clusterer module appears primarily to be a mechanism designed to help with scaling, distribution and load sharing in large multi-node VoIP projects. While this may be useful for some users, it is my experience that a single OpenSIPS server often has ample capacity for concurrent call handling and/or to deal with huge numbers of registrations. A greater challenge, in my experience, is the demand for a robust and resilient solution that can tolerate hardware or network failures and offer fast and seamless failover.
Clustering architectures
Terminology is not always precise. So let’s start by looking at a couple of definitions of clustering (in the context of IT systems design):
“In a computer system, a cluster is a group of servers and other resources that act like a single system and enable high availability and, in some cases, load balancing and parallel processing.” Source: techtarget.com
“Connecting two or more computers together in such a way that they behave like a single computer. Clustering is used for parallel processing, load balancing and fault tolerance.” Source: webopedia.com
Based on the above definitions, I would argue that a dual-site solution – where both sites are active and independently addressable – does not qualify as a cluster even though it’s primary purpose may be to provide fault tolerance, resilience or “high availability”. That is because, at a macro-level, it is not really acting like a single system. However, despite it not being a true clustered solution, you can still use the OpenSIPS clusterer module to great effect for data replication between two data centres as I will explain later in a later part of this article.
Furthermore, in my experience, it is extremely likely that the servers used to build an Internet Telephony Service will not be designed as a single monolithic clustered entity, but will instead be sliced-and-diced according to the application-level service they provide: Database server, SIP Proxy, Media Proxy, Web service, Radius/Billing service, etc.
In other words, the solution used within one data centre may comprise several interconnected clusters, where each cluster provides a defined application-level service. On top of that, a service provider may also have a second data centre which duplicates some, or all, of the services provided in the first DC. The dual DC solution might operate as an Active-Active arrangement or as an Active-Standby solution where the second site is only brought on-stream in a Disaster Recovery situation.
The role of Pacemaker in a clustered OpenSIPS solution
As mentioned, the purpose of the OpenSIPS cluster is assumed to be high availability rather than load sharing. So how might we cluster the OpenSIPS Proxy servers? In a much earlier article (here), I suggested using home-brewed bash scripts to control failover through the use of a floating or “virtual” IP address. However, I am gradually warming to the idea of using Pacemaker and Corosync for this purpose because (a) they are standard packages available on most Linux distros, (b) they are more scalable and (c) they can deliver much faster failover switching times.
Details of how to use Pacemaker to build a small cluster running OpenSIPS can be found in my article Pacemaker and OpenSIPS.
System Design Options
If you’ve just read the Smartvox article Pacemaker and OpenSIPS, you will appreciate that the overall architecture of a clustered solution can vary considerably especially with respect to:
- the distribution/location of the database or databases
- data replication mechanisms including the option to use the new Clusterer module
- the choice of Pacemaker resources and their configuration
As you will see in the examples that follow, the above three options cannot be designed in isolation because, in a real-world system, they all interact with each other.
Scenario 1 – single data centre and a shared clustered database
Enough theory. Let’s look at an example. Perversely, my first example is chosen to illustrate a scenario where the Clusterer module is not likely to be needed. I wanted to describe this case because it then allows me to explain how the alternatives, that do use Clusterer, are superior.
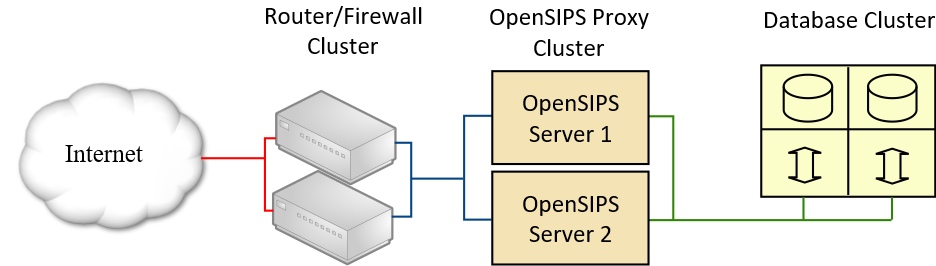
This diagram shows how we might design a solution for a single data centre. To illustrate my point about one data centre using several interconnected clusters, the above diagram shows the following clustered elements:
- The main router/firewall device
- The OpenSIPS Proxy servers
- The Database service
To a user this may appear to be a single system, but to a system designer it is three different clusters.
This article is not about how you cluster firewalls so I will not dwell on that element. Enough to say that higher end products from Cisco, Juniper, etc support clustering of your firewall hardware.
Database options and data replication
The above diagram shows a completely separate clustered database. Examples of technologies that could be used for this include MySQL Cluster (more details here) and Galera Cluster (more details here). The latter can be used with MariaDB which is especially nice if your infrastructure is based around CentOS 7 servers, but it also works fine on Debian. Database resilience using a distributed “NoSQL” product such as Couchbase is another alternative that would fit into the design pattern shown in the above diagram. A poor man’s database cluster, also fitting this design pattern, could be achieved using two or more independent MySQL servers configured with MySQL data replication and accessed using haproxy or the DB_VIRTUAL module.
It is assumed that both the OpenSIPS servers are reading from and writing to the same shared database/tables on the clustered database servers. While it would be possible to have one set of tables for server 1 and another for server 2, such a solution would better fit the description given in Scenario 2 shown a little further on in this article.
Pacemaker resources
Resources are the applications, services and functions that Pacemaker manages. The basic out-of-the-box packages come with support for a large number of these. The resource that is central to the OpenSIPS clustering solution being discussed here is ocf:heartbeat:IPaddr2
With a shared database, if a fault occurs on server 1 and Pacemaker decides to flip the VIP across to server 2, it is essential that the opensips service restarts on server 2 because this will ensure that OpenSIPS updates all cached data values for contacts and dialogs by reading them from the relevant database tables. This also means we do not have to be concerned about tricks to make the opensips service start on a server that does not have the VIP assigned to it. We can use the IPaddr2 resource to automatically assign a Virtual IP (VIP) address to one node or other (thereby making it the current active node in the cluster) and use the systemd:opensips resource to control the opensips service. This neatly achieves the goal of making two OpenSIPS servers “act like a single system” with considerable resilience and fast switching times in the event of one server node failing.
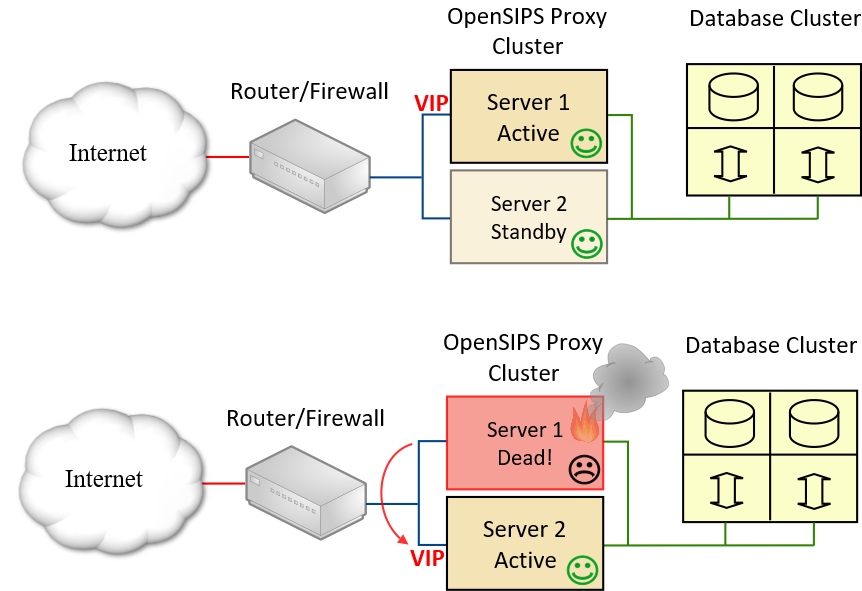
Please note that it is essential to use resource constraints to co-locate the IPaddr2 and systemd:opensips resources and to set the correct order for the two resources to start. Details are provided in the companion article Pacemaker and OpenSIPS.
The role of the OpenSIPS Clusterer module in this scenario
In this first example, there is no requirement to use the new Clusterer module because the database is shared. It is essentially a single entity and can be regarded as a “black box” with one, or perhaps two, defined points of access. Any data replication that is going on here happens inside the black box and is completely transparent to OpenSIPS.
Other OpenSIPS configuration issues in this example
In this example, we are using a shared database – both OpenSIPS servers are reading from and writing to the same tables. When the location table is shared between two servers, it is a requirement of OpenSIPS that the db_mode parameter in the USRLOC module be set to 3. I strongly advise against trying any other setting for this parameter if using a shared location table. Check carefully in the documentation for all the other modules used in your script in case they too require specific db_mode values when two servers are sharing the same tables.
If your clustered database has two or more access nodes, I recommend you take a look at the OpenSIPS module called DB_VIRTUAL. It allows you to define more than one URL for accessing the database.
Scenario 2 – locally hosted databases or one-database-per-server
My second example is quite similar to the first, but this time each OpenSIPS server is connected to its own unique instance of the database. The diagram shows this as locally hosted databases, but the configuration issues would be similar if you had two separate sets of tables on one clustered database server.
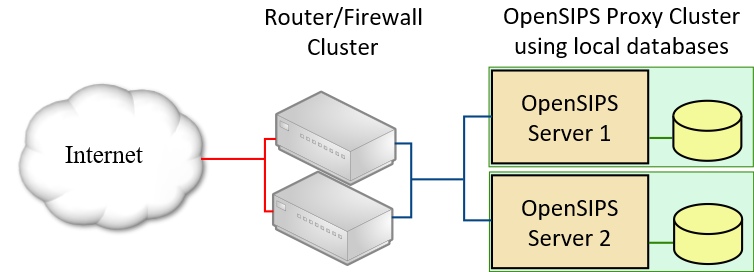
Data replication using the Clusterer module
In this example, we are not using a shared database and for replication we can instead use the OpenSIPS Clusterer module. This module allows two or more instances of OpenSIPS to synchronise critical dynamic data via a direct network connection using a compact, efficient protocol designed specifically for the job. Let’s consider the advantages of this strategy:
The biggest advantage of using the Clusterer module is that it avoids the need to restart the opensips service during failover, as was required in scenario 1. This means failover can be much faster. Furthermore, it is not necessary to use db_mode 3 for the USRLOC module. The drawback with db_mode set to 3 is that it hinders performance by preventing caching of contact data, forcing OpenSIPS to read and write directly to/from the location table every time there is any kind of update or query.
An aside: It should be noted that a mechanism is still required to replicate or synchronise certain static configuration data in those modules that are not integrated with the Clusterer module. That mechanism could be anything from crude manual data entry on each server through to automated replication using the DB server’s built-in functionality or even a bash or PHP script triggered every hour by cron. Fortunately, the data we are talking about do not change very often (usually) and are “foreground” configuration values, as might be viewed using an admin GUI, rather than “background” values being changed dynamically by the application in response to call activity and registration requests.
Pacemaker Resources and control of the OpenSIPS service
If we wish to use the Clusterer module it requires the opensips service to be active on both servers irrespective of which one currently holds the VIP address. This is necessary because the two instances of OpenSIPS have to communicate with each other using the “bin” protocol and that requires the opensips service to be running all the time.
The requirement to have the OpenSIPS service running on both cluster nodes raises a couple of problems:
- Default behaviour for the Pacemaker systemd agent is to allow a service to start on one node only
- When the opensips service starts, it attempts to bind to the interfaces defined in any “listen” statements. The service will fail to start if the address given in a listen statement is not currently assigned to any interface on the local host server, as would be the case on the standby server.
Both of these problems can be overcome. The simplest solution to problem 1 is to not control the service with Pacemaker. Instead, I used the standard systemd mechanisms and added the option “Restart=always” to the service unit file. However, there is another option available in the form of “resource cloning”. If you create a systemd resource to start the opensips service and then create a clone of it, then Pacemaker will start the resource on two nodes. For more info, try Googling for “Pacemaker resource clones”.
The solution to problem 2, as explained in my Pacemaker article, is to add a line to the file /etc/sysctl.conf that allows processes to start and bind to non-local IP’s.
The role of the Clusterer module in this scenario
In this scenario, we will only use the Clusterer module to duplicate registration details from one server to the other. It could also be used to duplicate dialog data, but for reasons of brevity I am not including details for this.
Configuration of the Clusterer module
The data are transmitted using the “bin” protocol (module proto_bin.so) and you must define an appropriate listen statement in opensips.cfg. I chose to use port 5678 for this purpose, so my listen statements looked like this:
# LAN interface listen=udp:192.168.3.125:5060 listen=bin:192.168.3.125:5678 # Virtual interface listen=udp:192.168.3.100:5060
Important note: The bin socket cannot listen on the VIP address and instead must use a static interface address of the host server.
It is necessary to load the proto_bin and clusterer modules:
loadmodule "proto_bin.so" loadmodule "clusterer.so"
…and there are a few parameter settings that should be included for these modules, as in the example code below:
modparam("proto_bin", "bin_port", 5678)
modparam("clusterer", "db_url", "mysql://dbuser:dbpassword@localhost/opensips")
modparam("clusterer", "server_id", 1)
Note: The value for “server_id” needs to be different on each node in the cluster – it will match the “machine_id” field in the database table. A lot of the Clusterer configuration data is read from a database table, not using modparam statements. I manually added lines to the clusterer table, creating a single cluster with an ID of 1, containing two server nodes. Its final contents for my test rig looked like this:
id cluster_id machine_id url state last_attempt failed_attempts no_tries duration description -- ---------- ---------- ---------------------- ----- ------------ --------------- -------- -------- ----------- 1 1 1 bin:192.168.3.125:5678 1 0 3 0 20 Test-vSvr2A 2 1 2 bin:192.168.3.126:5678 1 0 3 0 20 Test-vSvr2B
Replication of registered device contacts needs additional parameters for the USRLOC module. The following would do for a cluster ID of 1:
modparam("usrloc", "db_mode", 1)
modparam("usrloc", "replicate_contacts_to", 1)
modparam("usrloc", "accept_replicated_contacts", 1)
How does it perform under test?
There’s a lot to discuss under this heading so I’ve decided to end here, calling this Part 1; then I’ve written a new article – part 2 – which contains the discussion about testing of this scenario and about the practical problems I encountered.
Please take a look at part 2 to see how the Clusterer module performed when put through its paces as part of a Highly Available cluster solution here:
https://kb.smartvox.co.uk/opensips/using-the-clusterer-module-for-contact-replication/.
Finally, I’m going to look at another scenario – dual site – but that will eventually end up as part 3. Unfortunately, part 3 has not been written yet so you’ll have to wait a while for that.
Any idea when you might have part 3 done? I am in this exact situation. Clusterer module or DB replication in combination with VIP takes care of local HA. However, I also need datacenter and regional redundancy. I find that datacenters do go down no matter who it is and there are times when regions have problems as well. Total regional blackout is rare but brownouts are not. Sometimes due to one route having DDoS issues or what not.
So I need datacenter and regional redundancy. So ideally I need one IP on the east coast and one IP on the west coast. End users should be able to register and authenticate to either using the same account/credentials. NAPTR SRV is not ideal because not all UAC/UAS devices support it or failover properly.
So on a PBX I would create a primary and secondary SIP trunk. On a hard phone I would use primary and secondary server feature. Softphones that do not support primary/secondary server would use one or the other and would manually switch in the event of a problem.
I’d kind of forgotten about part 3 – paying work came along and got in the way! My other excuse is that the clustering solution got a major re-work done for v2.4. Bear in mind that v2.4.1 was only released yesterday and that’s the first truly stable release of the new clustering. There are several key areas – you’ve identified a big one which is how you get the client devices to be aware of two data centres. SRV records should be just the job, but as you say actual behaviour is too unpredictable. The OpenSIPS developers are quite keen on anycast, but I am not sufficiently up-to-speed on that to be able to help or comment. Another key area is deciding why the two data centres need to synchronise data and, consequently, what data must be synchronised. If both DC’s can be operational at the same time, then you may want to synchronise active call counts, rate limiting, etc so that users aren’t able to exceed agreed limits. Synchronisation of registrations isn’t necessary if the client device is able to register at both. Furthermore, synchronising registrations would probably be of little use because many customer devices are behind NAT. Their NAT firewall will only accept SIP requests from the IP address where the registration was made, so a call coming from the other DC would not get through (unless some anycast magic allowed both DC’s to use the same IP, which sounds too good to be true IMO). However, the new clusterer stuff in v2.4.x does allow some clever tricks where it can redirect requests to the “home” server – i.e. the one where the user is registered.
With a PBX, using primary and secondary trunks provides a solution for calls from the PBX to your service. But what about calls going in the other direction, service-to-PBX? This not only requires knowledge of how to reach the customer’s PBX from both DC’s but also means your call routing logic (further back in the chain) must know to try one DC first, then the other if the first is off-line. That probably means your carriers should have a connection to each of your data centres and they should deliver to one or other depending on availability.
The things relevant to dual data centre solutions supported by the OpenSIPS Clusterer Module are mostly from the DIALOG module (dialog replication and/or profile replication), the RATELIMIT module and the LOAD_BALANCER module (gateway status replication). The TM module uses clusterer magic, but I think this is mainly for anycast.
If you want to continue this discussion, drop me an email at john.quick (at) smartvox.co.uk