Why cluster OpenSIPS?
Unlike Asterisk, a typical OpenSIPS server is able to handle a very large number of simultaneous SIP calls. It is generally very reliable and will keep running for many months, or even years, with little or no attention. As a consequence, it is the preferred choice for many VoIP service providers who use OpenSIPS as the primary public-facing portal into – and often out of – their voice infrastructure.
This is fine as long as the server keeps running, but it means the OpenSIPS server has the potential to bring down most of your services in one go if you should be so unlucky as to have a hardware failure on the box it runs on. It also makes it incredibly difficult to do maintenance on the server or to update the OpenSIPS control script when you want to add enhancements or fix bugs.
The answer, of course, is to somehow cluster two or more OpenSIPS servers so they provide a “High Availability” solution. However, this turns out to not be as simple as one would hope. Issues that have to be considered include the location of, and shared access to, a common database of key data, most notably the location table. There are further issues concerning far-end NAT traversal and the IP address of the OpenSIPS server. In this article, I will describe how we overcame the problems and successfully configured two OpenSIPS servers to operate as a cluster capable of automatic failover – from a primary to a backup unit – in less than 30 seconds.
Supported OpenSIPS modules and features
The clustered OpenSIPS servers operate as a SIP Registrar, with support for far-end NAT traversal, as well as the more mundane role of acting as an inbound/outbound SIP proxy server for calls to and from carriers. We use AG-Project’s Mediaproxy for far-end NAT traversal and a MySQL cluster database server to store lists of trusted peers, subscriber account details and various items of dynamic “real-time” data including the location table.
The main OpenSIPS modules in use are as follows: For subscriber authentication and database storage – db_mysql.so, auth.so, auth_db.so, acc.so, userloc.so and registrar.so; For far-end NAT traversal – nathelper.so, nat_traversal.so and mediaproxy.so; For peer, domain and group matching – permissions.so, domain.so and group.so; For general handling and manipulation of SIP messages – sl.so, tm.so, rr.so, signalling.so, dialog.so, uac.so, uri.so, textops.so and avpops.so.
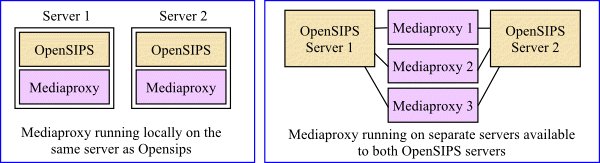
Multiple Mediaproxy servers
You can install and run an instance of Mediaproxy directly on each of the OpenSIPS server, but it is also possible to run additional Mediaproxy relay servers alongside your OpenSIPS server. This ability to interlink SIP and Mediaproxy servers provides the basis for a solution that is both scalable and resilient.
Storing data on MySQL servers
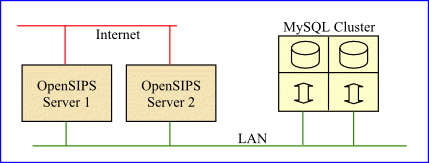
For clustering to work it is essential that key information, such as registration locations, be stored off the primary OpenSIPS server. In my opinion, hosting the database and OpenSIPS applications on different servers makes it much easier to understand how data synchronisation will work for all possible cases and, because it is very unlikely that two different servers would fail at the same time, you should only ever have to deal with one problem at a time when disaster strikes.
Probably the best solution would be to store all data on a separate MySQL Cluster. This provides a resilient storage solution and has the flexibility to allow replication to other sites, automated backups and other features required for a high availability system. [2017 Update: Galera Cluster is an alternative product well worth consideration]
 |
||
If you don’t want the expense of a full-blown MySQL cluster then it should be possible to use proprietry load balancing/failover units – such as Kemp Technology’s Load Master – to automatically select one of two ordinary MySQL servers. It would be necessary to synchronise the data across the two servers, but the details of that mechanism are outside the scope of this article.
Shared data and registrations
There are two types of data that are likely to be updated frequently on an OpenSIPS server – Call Data Records (CDR’s), for billing, and location data collected when UA devices register with the server. Ensuring the continued collection of CDR’s following a failover should not present the system designer with too many problems because CDR’s can even be written to more than one location and merged later. However, the data that OpenSIPS stores in the location table presents a fairly unique set of problems, especially when far-end NAT traversal is being used.
Clock synchronisation
One important, but easily overlooked, detail is the need to ensure that the clocks on both OpenSIPS servers are synchronised and show the same date and time. We use ntpd to keep the clocks correct from an independent external time source.
The importance of clock synchronisation is best illustrated by an example. Suppose that a user device registers with Server 1 at 09:35 and the registration expires after one hour. If Server 2 is sharing the same location table and the clock on Server 2 is one hour ahead (i.e. it thinks the time is 10:35) then the registration will immediately appear to be expired to Server 2. Server 2 will then delete the registration from the location table and both servers will now be unable to send calls to the client device.
NAT Traversal
It is tempting to think that two OpenSIPS servers could simply share the same location table and that user devices, such as IP phones, could then register with either server. Surely, both servers would be able to read the location data whenever they need to deliver a call to the UA device. Where’s the problem?
First, if you want to share the location table, you must set the db_mode for the userloc module to 3. If you don’t then you will hit snags with local caching of location data (which may render one server’s registrations invisible to the other) and with errors from OpenSIPS along the lines of “unmatched source socket”.
So why is the source socket written to the table and why does OpenSIPS check to see if it matches when using the location data? The key to understanding that lies in an appreciation of the problems of far-end NAT traversal from two different servers – only when you grasp that can you see why OpenSIPS clustering is not a simple problem at all. I will discuss this is detail in part 2.
2 thoughts on “Clustering OpenSIPS for High Availability – Part 1”
Comments are closed.