
Summary
In this article we examine how Pacemaker and Corosync might be used to supercharge OpenSIPS and build a highly available clustered solution. The focus is entirely on High Availability rather than any form of load sharing. This means we are looking for a way to have more than one server contactable on the same IP address.
The starting point is assumed to be a pair of similar or identical servers connected on the same subnet, each running an instance of the opensips service (for all tests I was using OpenSIPS version 2.2.x).
A quick tour of Pacemaker concepts
Pacemaker and its sidekick Corosync are available as easily installed packages on most Linux distros. They are used to create and manage clusters. A cluster is simply a group of inter-connected servers that, at the application level, behave like a single system to provide high availability or load sharing. Each server within the cluster is referred to as a node.
Corosync provides a communication framework within which nodes are aware of each other and can communicate with each other regarding their own state and their awareness of the network environment around them. Corosync also acts as an event generator alerting the management system, through an API, of changes when they are detected.
Pacemaker is the management system that sits on top of Corosync (or a similar compatible communication backbone). Pacemaker manages one or more resources, where a resource is typically a service or facility running on the servers. The out-of-the-box installation usually includes support, in the form of agents, for a large number of potential resources. You are likely to only need a small number of these.
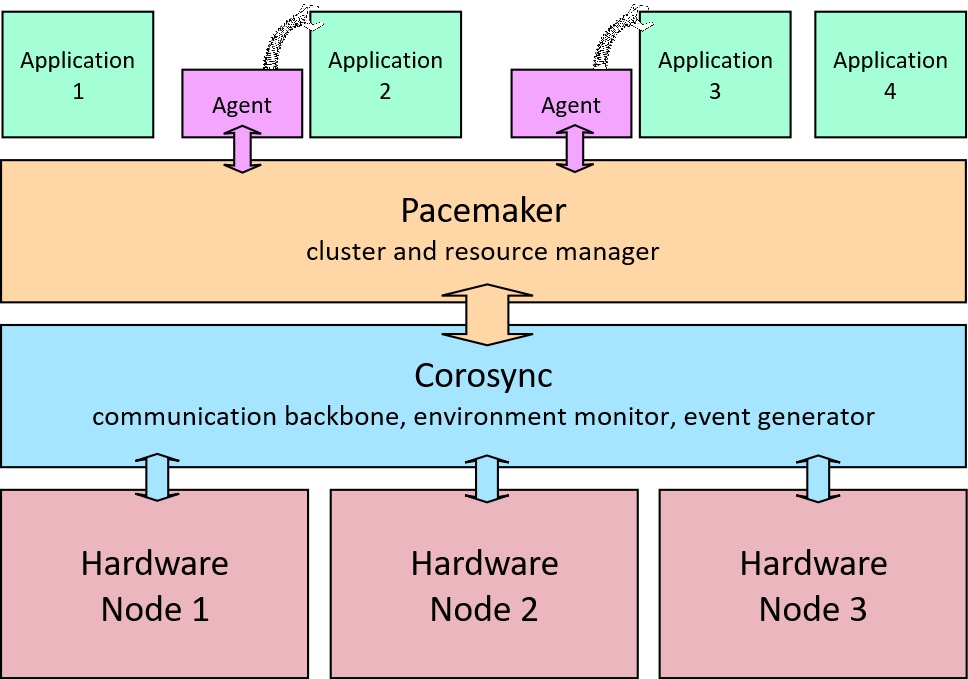
Agents are sub-divided according to “standard” and “provider”. Standards include ocf, systemd, stonith, etc. Providers include heartbeat and pacemaker itself.
Command line management and configuration tools (shells) are generally available alongside the pacemaker package – on newer CentOS or RedHat servers this is generally pcs and on Debian it is likely to be crm. These should provide a command that can be used to list the available resources. For example, using pcs the following commands will show a list of known standards, list of known providers and then a list of agents provided by heartbeat and using the ocf standard:
pcs resource standards pcs resource providers pcs resource agents ocf:heartbeat
The resource agent that is of most interest to us is the ocf heartbeat agent called IPaddr2. It provides a mechanism for dynamically assigning a floating or ‘Virtual IP’ address to one node in a multi-node cluster.
Installing Pacemaker and Corosync
There is no point providing full step-by-step instructions for installing the Linux HA platform here because there are a number of existing online articles that cover the topic very well. I would recommend the following:
- General information – http://clusterlabs.org/
- Step-by-step instructions for Ubuntu – https://www.digitalocean.com/ …tutorials…
- Step-by-step instructions for CentOS 7 – http://jensd.be/156/linux/building-a-high-available-failover-cluster…
- This Packt book covers all the essentials for CentOS 7 users: CentOS High Availability by Mitja Resman (furthermore, the embedded link currently opens an Amazon “preview” that seems to give free access to all 155 pages )
One tip I would offer regarding basic configuration is, from the outset, to edit the /etc/hosts file on every node in the cluster and make sure the primary IP address of every cluster node is listed along with the computer name you are using in your cluster configuration commands. For example, this is what my /etc/hosts file looked like when I was setting up a test rig on my LAN with three server nodes:
127.0.0.1 localhost localhost.localdomain ::1 localhost localhost.localdomain localhost6 localhost6.localdomain6 192.168.3.125 Test-vSvr2A 192.168.3.126 Test-vSvr2B 192.168.3.130 Test-vSvr3
Once the packages have been installed and the basic Corosync configuration (access details, server names, cluster created, nodes defined, etc) is completed, you will need to create and configure resources.
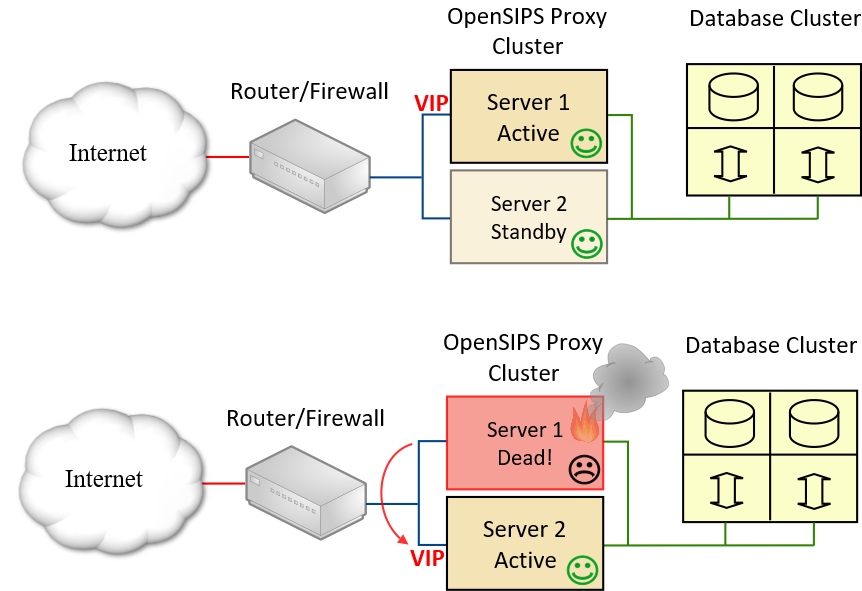
Using the IPaddr2 agent with OpenSIPS
As mentioned above, the IPaddr2 agent provides a facility for automatically assigning a floating or ‘Virtual IP’ (VIP) address to one node in the cluster. We are trying achieve the goal of making two OpenSIPS servers “act like a single system” and the simplest way to do this is to have the primary target address for OpenSIPS (as seen by the rest of the network) as the VIP address and for Pacemaker to control which of our two OpenSIPS servers currently holds the VIP address. For an OpenSIPS cluster, this effectively means that the current active node in the cluster is the one that has the VIP. You then have to get used to switching the active node back and forth using the relevant pcs or crm commands – for example, momentarily switching a node to “standby” will cause Pacemaker to assign the VIP to the other node (provided it is still “online”). Always remember to set the node back to an “online” status after switching it to standby or you risk complete failure should both nodes be in standby mode.
Ideally, we might want the opensips service to be active on both servers irrespective of which one currently holds the VIP address. However, there is a problem with this – when the opensips service starts it attempts to bind to the interfaces defined in any “listen” statements. The service will fail to start if the address given in a listen statement is not currently assigned to any interface on the local host server, as would be the case on the standby server. Thus, we must choose one of the following options:
- Automatically start the opensips service on the node that receives the VIP and stop it on the node that looses the VIP
- Find a trick that allows the opensips service to start (and keep running) on a node even when that node does not have the VIP
If we choose option 1, the solution lies within Pacemaker itself because there are agents available to control the facilities that start and stop services. For example, you could use the systemd agent to manage and control the opensips service. Other agents are available for non-systemd Linux distros. Please note that you will also need to configure resource constraints to ensure the two resources are colocated and that they start in the right order. Details are given below.
If we choose option 2, the best solution I know of is to edit the file /etc/sysctl.conf and add the following line:
net.ipv4.ip_nonlocal_bind = 1
This allows the opensips service to start even if the config script contains listen statements for IP addresses that are not currently assigned to a local interface. Note that changes to the sysctl.conf file only become effective following a reboot of the server. If you now want the opensips service to be controlled by Pacemaker and you also want the service to be active on more than one node at the same time, it is possible to do this by creating a systemd resource, as mentioned above, and then apply resource cloning.
Using Pacemaker resource constraints to co-locate IPaddr2 and SystemD
A quirk of Pacemaker’s default behaviour is that it will attempt to spread resources fairly evenly across your cluster nodes. In other words if there are two nodes and two resources, it will assign one resource to each node. It is trying to be helpful by doing some load sharing, but when one of the resources is IPaddr2 it may actually be doing the opposite of what you want! In the case of option 1 above, we require the opensips service to run on the cluster node that currently has the Virtual IP address.
The solution comes in the form of “resource constraints”. First you need one that tells Pacemaker to co-locate the two resources; then you need another to tell Pacemaker that the floating IP address must be assigned first before the opensips service is allowed to start. The pcs commands to do this are as follows (I’ve used resource names of “ClusterIP” for IPaddr2 and “OSIPS” for the systemd resource that controls the opensips service):
pcs constraint colocation add OSIPS ClusterIP INFINITY pcs constraint order ClusterIP then OSIPS
Under test – does it work?
The solution described above provides a starting point on the road towards a resilient highly-available system, but the job is by no means complete and there are design choices that need to be made in the light of your own expectations. Let me explain in a little more detail.
What will trigger failover?
Kill the power to server 1 and pacemaker will very quickly re-assign the VIP to server 2. Great, we can tick that box.
However, if the opensips service stops with a segfault then pacemaker might restart the service after a delay, but only if you configured a resource agent to start and stop the opensips service. If you chose not to use a resource agent to start the service then you can achieve the same result by adding the parameter “Restart=always” in your systemd unit file.
If you deliberately stop the opensips service on the active node (for example, using the command “systemctl stop opensips”) then Pacemaker will probably not restart the service or flip the VIP across to the other server.
Suppose you wanted to make a small change to the opensips.cfg config file, but you made a mistake and broke the script with a syntax error. When you restart the opensips service and see that dreaded “service failed to start” message, you might hope that Pacemaker would come to the rescue and save you from the embarrassment of having to explain to your boss what happened. No such luck I’m afraid! Even though the backup server is still viable (where we hope the old error-free version of the script is still in place), Pacemaker – using the basic configuration described in this article – will almost certainly just keep trying to restart the opensips service with the dodgy config file on server 1.
Failover stickiness
The default behaviour for Pacemaker, when failover is triggered, is to then leave the resources running on the new node even if the original fault that triggered failover is fixed on the old one. If you do not want this behaviour, it is necessary to assign a resource location constraint that instructs Pacemaker to “prefer” one node or another. A command like this, although node and resource names may differ, should do:
pcs constraint location OSIPS prefers Test-vSvr2A=50
What about the database?
What arrangement does your OpenSIPS server use for storing persistent data? The most commonly used solution is a MySQL database, but this could be running on the same server (localhost) or could be on a remote address. The remote system might be a single server or a complex clustered highly-available solution such as MySQL Cluster or Galera Cluster.
Now that we have two OpenSIPS servers arranged as a cluster, should each server be pointing to a different database or should they both be pointed at the same “shared” database? There is no “right answer” I’m afraid. You have to make that decision based on knowledge of reliability and resilience of the remote database system. Also, it depends a lot on whether a mechanism for data replication exists. Data replication is possible between database servers, but since version 2.2 of OpenSIPS was released, it is also possible for OpenSIPS to provide limited replication of data – registration contacts (the location table) and dialogs at least.
Will calls be dropped when failover is triggered?
This depends very much on the path being used for the RTP media and on how widespread the fault is that triggered failover. If it was a local fault on just one of your OpenSIPS servers and that server had no role in handling the RTP media then existing calls should continue uninterrupted. The SIP messages are mostly sent and received when a call is set up and when it ends. During the call, there are a lot of RTP packets flowing but very few SIP messages being exchanged.
When RTPproxy or Mediaproxy are used, you may prefer to host them on different servers to OpenSIPS. This spreads the risk and makes it less likely that calls will be dropped when a problem happens.
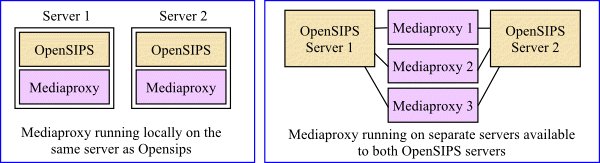
However, it is very difficult to avoid the risk that audio would stop on many calls should one of your mediaproxy servers die.
Conclusions
Pacemaker and Corosync give us an excellent tool kit that can be used to great effect, especially for management of a virtual IP address shared between two or more servers in a cluster. However, it has to be seen as just one piece of the jigsaw. Building a resilient highly-available solution is a multi-faceted problem and the overall shape and architecture of your design will depend on a wide range of factors, not least your own expectations for reliability and cost.
Hi thanks for the article. Did I just miss it, or how do you manage a case of split brain where it decides to bring up the VIP on both nodes?
Thanks!
It should never bring up the VIP on both nodes. Two nodes both having the same IP address would only work if you had support for anycast. That is a whole new topic – this article makes no attempt to cover that topic.
Thank you, your doc is very helpfull.
i did that and i have an issue on something.
when we stop opensips1 (node1) and opensips2 (node2) getting the virtual ip is working correctly. but if we want to stop node2 to go back on node1 we are having 10 min delay (all the ips are public) until virtual ip be accessible.
Hi Manos. I actually did more work on this after writing that article, but even so, it was quite a long time ago now and my memory is a little hazy.
I still have the two servers running here and operating as a cluster controlled by Pacemaker. They seem to switch over pretty quickly – a lot less than 10 minutes.
It required quite a lot more tinkering to get to that point. The main feature being a separate application (actually just a bash script) that constantly checks if the OpenSIPS service is running. It uses two different tests to check. If both tests confirm that opensips has stopped, then it exits. Then I put this monitoring service under the direct control of Pacemaker instead of putting the OpenSIPS service under direct control. OpenSIPS is just under the usual control of systemd. This sounds a bit crazy, but it was the only way I could make it so Pacemaker wouldn’t just keep trying to restart the opensips service on the node where you shut it down. Then I tinkered with several of the timeout values inside Pacemaker to improve the response time.
I’ve got some notes I made at the time and would be happy to email them across to you, but if you need me to get heavily involved and assist you or answer lots of emails then I would have to do it as chargeable work. I’ll email you.
John
Thank you! Very useful article