
In this, part 3, we examine how a virtual IP address can be switched between two Linux servers to provide an active/standby failover and how this impacts on OpenSIPS.
Part 2 investigated the implications for far-end NAT traversal of clustering two OpenSIPS servers and concluded that the best solution is the use of a virtual IP address.
Summarising the design so far
If you read the first two parts of this article, you will appreciate how and why we reached the decision to cluster two OpenSIPS servers in an active/standby mode using a shared database server and a so-called Virtual IP address as the primary contact address for the cluster.
Our cluster design now looks like this: Two almost identical servers, both configured to run OpenSIPS and both accessing the same shared database for storage of the location table and other key data. Each server has two network interfaces – one connecting it to the Internet and the other connecting it to a LAN where the database server resides. At the Internet interface, each server has its own unique IP address (the real address) and, at any given time, either one of the two servers may also hold the virtual IP address.
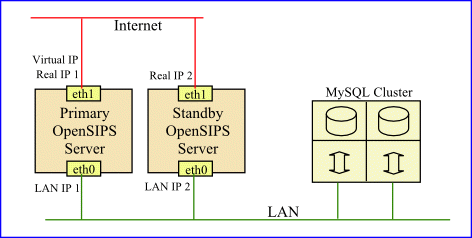 |
|
The AG-Projects’ mediaproxy application is also running on one or more servers, although there is some element of choice regarding the exact configuration so they are not shown in the diagram above.
Putting it into practice
Note that you need three static IP addresses for the two servers in the cluster – 2 real and 1 virtual. All three Internet IP addresses have to be in the same subnet and use the same default gateway for routing. I wrote some bash scripts that allowed each node in my 2-node cluster to monitor the other as well as their own connectivity to the Internet. The scripts had logic to decide which should be allocated the VIP and to assign it accordingly. There is no magic here, the commands to enable or disable the virtual IP address on one of the servers are remarkably simple:
- ifconfig eth1:1 <VIP> up
- ifconfig eth1:1 down
However, make sure you never enable the VIP on both servers at the same time.
Default routing on each server needs to be configured so that the correct interface is used for communication with peers on the LAN and for peers on the Internet. However, I found it is not sufficient to simply rely on the operating system’s routing plan to sort out everything immediately after a switch of the VIP (Virtual IP) address. You also need to make OpenSIPS listen on that address on the interface and the only way I could find to do that, after enabling the VIP, was by restarting the OpenSIPS application. Another little trick that is needed is to broadcast ARP updates so that immediate neighbours update their ARP tables and are able to find the new location of the VIP.
OpenSIPS on multi-homed server
As mentioned above, OpenSIPS has to bind (or listen) to the VIP interface before it can use it. The administrator is given two options in opensips.cfg – you can explicitly define one or more combos of “interface/address/port” using the “listen” directive or you can omit the listen directive in which case OpenSIPS will listen on all interfaces:
examples of explicit listen instructions: listen=eth1:5062 listen=udp:10.10.10.10:5064In practice, explicit binding would be difficult to use here because OpenSIPS generates an error if started with an explicit binding to an interface address that is not running on the host machine. Instead, I found it best to use default binding (i.e. no “listen” directives) and let OpenSIPS find all the interfaces on the machine when it starts. However, be aware that you still need to restart OpenSIPS each time you change the network settings, even if using default binding. Hence, a restart is needed after the VIP is enabled or disabled.
[2017 update: It is possible to change the default behaviour on Linux so it allows applications to bind to an IP address that is not yet assigned. The trick is to edit the file /etc/sysctl.conf and add a line like this
net.ipv4.ip_nonlocal_bind = 1
then reboot]
Once OpenSIPS is running and has bound to all the interfaces (that is three on the active member of the cluster – one LAN, one real IP and one Virtual IP), which one will it use when it sends a SIP packet to another peer or to a SIP client device? Again, you have some options here when using OpenSIPS. It is possible to explicitly define the protocol, address and port by calling the force_send_socket function at the appropriate point in the opensips.cfg control script. However, I was interested to see what it would do if left to make the decision unaided and, generally, the logic seemed to be spot on. For example, if a request arrived on the real IP address on eth1, OpenSIPS would respond, or forward subsequent requests in that transaction, using the same interface and real IP address. Equally, if the request arrived on the VIP, then responses and relays would also use the VIP. However, if the destination of a request was a registered UA then OpenSIPS would relay the request to the UA using the same interface and address that the UA had used when it registered. The reason for doing this may not be immediately obvious, but if you go back and read the explanations of far-end NAT traversal in part 2 you will soon realise why that is the right thing to do.
That deals with most of the issues arising from running OpenSIPS on a multi-homed server, but there is one more quite subtle point worthy of note. Most scripts are likely to add a Record-Route header. This is a header that tells the downstream device to remember the route taken and, if it needs to generate any new upstream transaction requests later in the call, it should send them first to our OpenSIPS server and not send them direct to the other end-point. The Record-Route header can also be useful for storing one or two parameters such as “nat=yes”. When you explicitly specify the contents of the Record-Route header by calling the record_route_preset function, the parameter string you pass to the function includes the IP address (and port) to be used for so-called loose-routed messages later in the session. If your server has more than one IP address then you may want to match the address passed to this function with the address that received the incoming request. For this you can use the keyword dst_ip in a string comparison test to see which interface received the request.
Automatic failover
When a fault occurs, failover needs to operate quickly and without human intervention (after all, we all know that systems fail when the most experienced engineer is out of the office and cannot be contacted).
To automate the failover process, we used cron to run a small bash script every minute – a different script was required on the primary and the backup server. Furthermore, to make the automated failover process respond more quickly, the script activated by cron was a timed loop that called the real script four times every minute. In this way, and following some fine tuning, tests showed that failover from primary to backup usually took less than 20 seconds. While not perfect, it is a lot better than any manually switched solution – unless of course you like to see which customers will complain first! [2017 update: If you use Corosync, Pacemaker and pcs the switchover is very fast – just a few seconds]
Conclusion
You might be disappointed to find that I have not published the scripts as part of this article, but it would hardly be fair to those Smartvox clients who contributed financially towards the development of the clustering solution if I did. If you want to develop your own automated failover scripts then the advice and tips provided in these articles should help you to overcome issues specific to OpenSIPS.
If you don’t want to get involved in the development cycle or don’t have the resources to do the work in-house, Smartvox would be happy to assist you with configuration of two existing OpenSIPS servers to turn them into a clustered pair. Our preferred platform is CentOS and we can work remotely using SSH either direct or via VPN. Remember, this solution requires three static Internet IP addresses for the two OpenSIPS servers – without that, it is not possible. Enquiries by email please to info(at)smartvox.co.uk.
Why not just use Linux-HA for failover? http://linux-ha.org/wiki/Heartbeat
Linux-HA (or Heartbeat) would be a good alternative – in the end it is just another virtual IP solution. However, writing your own scripts to switch between servers has the advantage of giving you complete control over the process.
I researched the standard HA solutions when I first wanted to install a clustered OpenSIPS solution and I concluded that the older versions were too stale and the newer releases seemed over-complex and bloated. As I recall, I started to install HA, got bored and decided it was going to be easier to modify some scripts I already had for an Asterisk failover solution.
You’re welcome to use HA, but the issues discussed in parts 1 and 2 of this article still apply.